
wenda-一个输出效果不亚于大模型的有趣开源自然语言模型
前言
本文简单记录一下wenda本地使用情况。
wenda,是一个支持本地知识库的,支持联网搜索的,实现类似AutoGPT查询总结输出的,使用小模型达到效果不亚于ChatGPT的开源自然语言模型。
正文
一、wenda介绍
闻达是一个LLM调用平台,旨在为小模型外挂知识库查找的方式,实现类似于大模型的生成能力。支持chatGLM-6B、chatRWKV、chatYuan、llama系列模型,提供自动保存对话历史、知识库扩展模型能力、参数在线调整、局域网、内网部署和多用户同时使用等功能。
二、wenda安装
1、安装wenda
下载项目文件,安装通用依赖,
1 | git clone https://github.com/l15y/wenda.git |
根据要使用的模型分别安装不同的依赖库。
2、下载LLM模型
推荐使用ChatGLM-6B-int4和RWKV-4-Raven-7B-v10模型,ChatGLM-6B-int4可以在6G显存或内存上运行,RWKV根据分配策略而定。
- ChatGLM
ChatGLM-6B是一个开源的、支持中英双语的对话语言模型,基于General Language Model(GLM)架构,具有62亿参数。用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存),并使用P-Tuning v2的高效参数微调方法定制自己的应用场景。需要注意的是目前该模型具有相当多的局限性,如可能生成有害/有偏见内容等。
官方提供了懒人包下载,里面有程序主体和多个模型,也可以在huggingface上寻找更优化的模型版本。
如果要使用Apple Silicon的GPU运行,需要修改config.xml文件中的GLM6B策略项为mps fp16,再在plugins/llm_glm6b.py文件中增加两行:
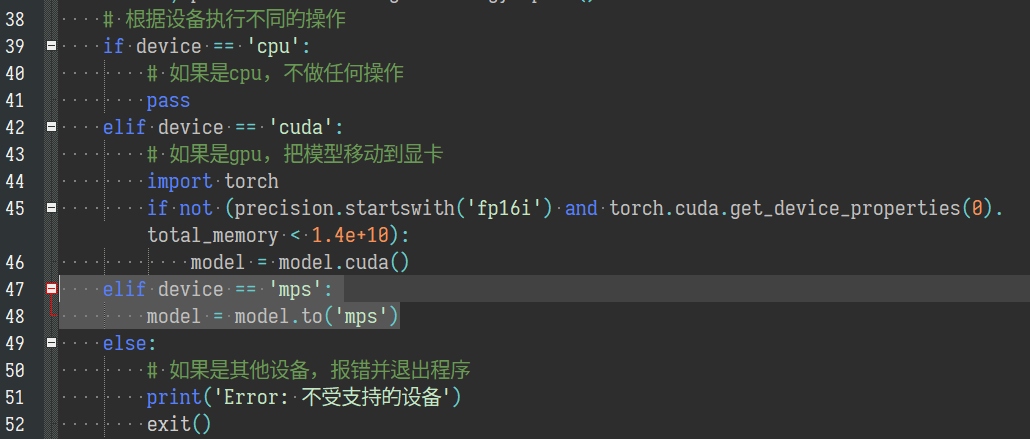
- RWKV
ChatRWKV是一个类似于ChatGPT但由RWKV(100% RNN)语言模型功驱动的聊天工具,可扩展性和质量与transformer相当,且速度更快且可节约VRAM。它还提供了v2版本,包括流和分离策略以及INT8。用户应注意在构建ChatRWKV聊天机器人时检查状态的文本以防止错误,并使用推荐的格式进行聊天。
目前RWKV有大量模型,对应各种场景,各种语言:
- Raven模型:适合直接聊天,适合+i指令。有很多种语言的版本,看清楚用哪个。适合聊天、完成任务、写代码。可以作为任务去写文稿、大纲、故事、诗歌等等,但文笔不如testNovel系列模型。
- Novel-ChnEng模型:中英文小说模型,可以用+gen生成世界设定(如果会写prompt,可以控制下文剧情和人物),可以写科幻奇幻。不适合聊天,不适合 +i 指令。
- Novel-Chn模型:纯中文网文模型,只能用+gen续写网文(不能生成世界设定等等),但是写网文写得更好(也更小白文,适合写男频女频)。不适合聊天,不适合 +i 指令。
- Novel-ChnEng-ChnPro模型:将Novel-ChnEng在高质量作品微调(名著,科幻,奇幻,古典,翻译,等等)。
wenda里推荐使用RWKV-4-Raven-7B-v10-Eng49%-Chn50%-Other1%-20230420-ctx4096,可以在huggingfaces上下载各个版本。
RWKV的模型策略有如下选择:
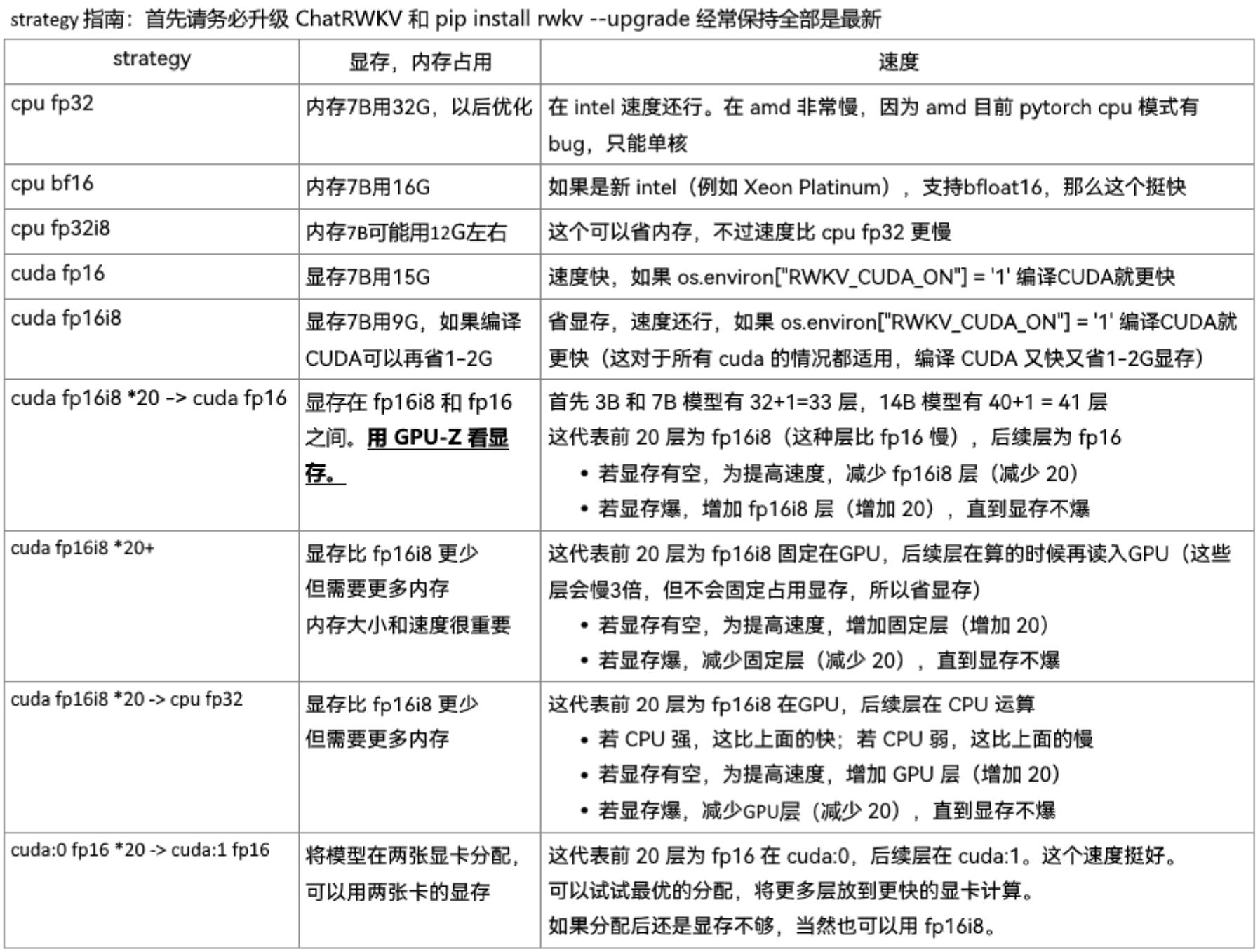
RWKV-4-Raven-7B-v10模型有13G大小,如果使用cuda fp16加载需要15G+的显存,对于普通消费级显卡不友好,所有可以选择cuda fp16i8 *20+这种策略,如果显存还是不够就减少层数,比如*18+,这是流式使用GPU,在速度上会比全部加载要慢。甚至有人更极限,在2G显存跑,可以参考这篇文章,使用cuda fp16i8 *0+ -> cpu fp32 *1策略。
如果显存足够还是全加载cuda吧,RWKV相比ChatGLM在同参数量上速度有很大优势。
编译RWKV的cuda_kernel
在RWKV中还有一个环境变量RWKV_CUDA_ON,可以编译RWKV的cuda_kernel,进一步加速推理(虽然我的卡不加速也很快:lol:),需要gcc5+,配置CUDA_HOME,我的测试环境是Pytorch1.12,cuda是11.3,在编译kernel时报错 #error You need C++14 to compile PyTorch,这时候需要修改rwkv库中的model.py文件,将编译选项-std=c++17修改为-std=c++14即可完成编译。
- LLaMa
llama系的模型有很多,推荐vicuna-13B,选择使用ggml int4量化版本,在此处下载。
需要注意的是在安装llama-cpp-python时,有些机器编译失败,需要使用gcc11可以编译成功,下面是编译gcc11和使用gcc11编译llama-cpp-python的步骤:
编译安装gcc11
1 | git clone --branch releases/gcc-11.1.0 https://github.com/gcc-mirror/gcc.git |
编译安装llama-cpp-python
1 | export CC=/usr/local/gcc-11.1.0/bin/gcc |
- OpenAI API
wenda里还可以直接使用OpenAI的API,再配合知识库功能,效果会更好。
三、wenda使用
安装好项目主体,下载好模型后就可以配置config.xml文件了,在里面配置模型加载路径和知识库模式等参数。
知识库模式
知识库原理是生成一些提示信息,会插入到对话里面。
项目中的模式有如下几种:
- bing模式,cn.bing搜索,仅国内可用
- bingxs模式,cn.bing学术搜索,仅国内可用
- bingsite模式,bing站内搜索,需设置网址
- st模式,sentence_transformers+faiss进行索引
- mix模式,融合
- fess模式,本地部署的fess搜索,并进行关键词提取
可以分为在线和本地两类,在线则是使用bing搜索联网查询信息,本地则是使用个人知识补充。
具体可以参考官方模式介绍。
都配置好后执行python wenda.py即可访问url使用。
以下是使用RWKV模型时的测试效果:
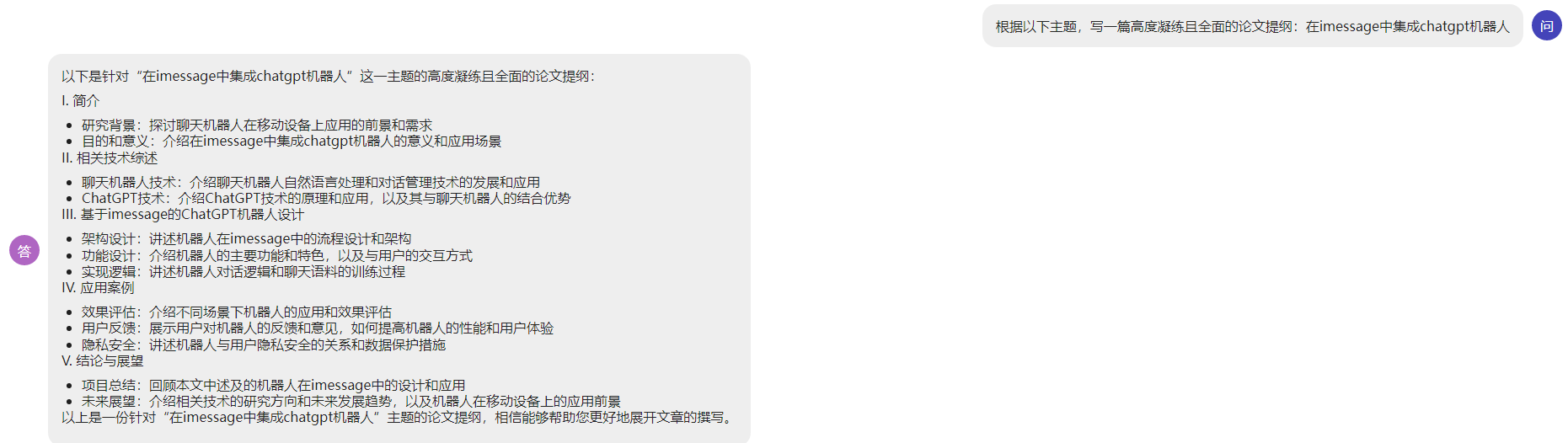
写论文的时候支持自动完成子目标的提问回答:
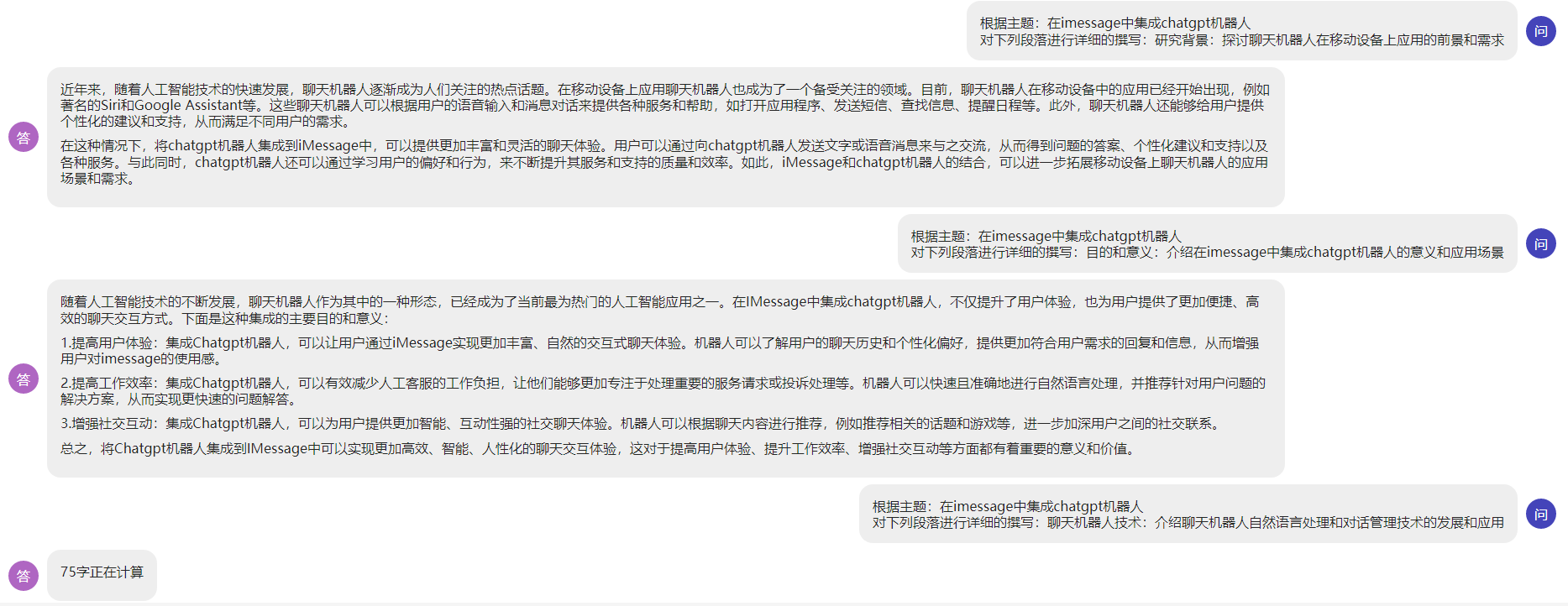
另一个话题的效果:

使用ChatGLM-6B-int4的测试效果:


感觉上ChatGLM-6B的效果要好,速度没看出什么差异。
至于llama系的测试结果太差,还是不要用了。
四、总结
使用下来体验还是不错的,要知道包括ChatGLM、RWKV、LLaMa、gpt4all还有LLaVa等模型,我都有试用过,这些模型相比ChatGPT在直接使用上的效果都差了那么些意思,而使用wenda进行测试的效果却让我惊讶,达到了四两拨千斤的效果,其中ChatGLM-6B的效果最好,同时在使用OpenAI API时还能得到更好的效果。
但是即使加了知识库的功能,在生成准确性上还是难以保证的,这个即使在ChatGPT上也会出现胡言乱语,所以使用时还是要仔细甄别内容有效性。
总体而言,在使用wenda时,模型选择不同时,这些模型都能够让我感受到自然而流畅的对话体验,对于想本地部署的人而言是非常棒的项目。
最后
参考文章:
声明
本文仅作为个人学习记录。
本文永久记录于区块链博客xlog。