
vits_chinese-流畅清晰的中文TTS
前言
本文简单记录介绍一下vits_chinese。
vits_chinese使用了BERT和VITS进行TTS,并加入了一些自然语言特性,从而实现高质量的文本转音频,同时支持实时输出。
正文
一、什么是VITS
VITS是一种采用变分推理和对抗性训练过程的声音合成模型,可生成比当前两阶段TTS系统更自然的音频。该模型采用随机时长预测器来从输入文本中合成具有不同节奏的语音,并通过概率建模和随机时长预测器表达自然的一对多关系,其中输入文本可以以不同的音调和节奏发音。
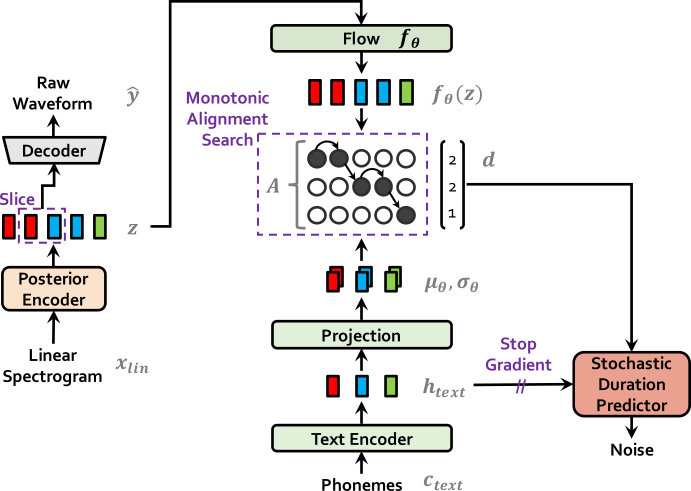
如下是vits的训练流程图:
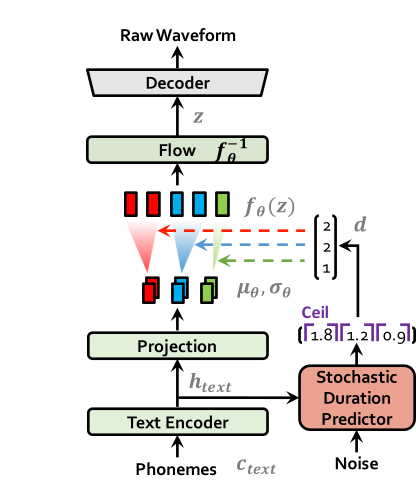
如下是vits的推理过程:
而vits_chinese使用vits作为模型框架,采用BERT作为内部基础组件,可以获取更自然的停顿、较少的声音错误和高音频质量。
二、vits_chinese功能
- 使用BERT获取自然停顿,实现自然语音
- 根据自然语音推断损失,减少声音误差
- 使用VITS的框架,提供高质量音频
三、vits_chinese使用与训练
可以在线体验demo。
如果要自己训练测试,需要先安装项目:
1 | pip install -r requirements.txt |
预训练模型可以在huggingface项目上或在网盘下载,
推理请执行:python vits_infer.py --config ./configs/bert_vits.json --model vits_bert_model.pth
训练可以下载baker数据,将波形的采样率更改为16kHz,并将波形放入./data/waves中,将000001-010000.txt放入./data中,然后运行python vits_prepare.py -c ./configs/bert_vits.json和python train.py -c configs/bert_vits.json -m bert_vits进行训练。
如果要自定义训练数据,只需要将数据整理成项目要求的格式即可。
四、总结
效果完全依赖语料数据集的覆盖程度,该项目也不算是一个完整的TTS项目。
项目只有一种女声,如果要更多可选项就需要自己收集语料训练了,整体效果非常不错。
最后
参考文章:
声明
本文仅作为个人学习记录。
本文永久记录于区块链博客xlog。