
CoDi-Any2Any的生成模型
Jun 3, 2023
前言
本文简单记录介绍一下CoDi。
CoDi可以从任何输入模态生成任何组合的输出模态,例如语言、图像、视频或音频。
正文
一、什么是CoDi
CoDi可以从任何输入模态,比如语言、图像、视频或音频的任何组合中产生任何语言、图像、视频或音频输出模态的组合。它在输入和输出空间中对齐模态,通过在扩散过程中桥接对齐来构建共享的多模态空间,使其能够对任何输入组合进行条件,并生成任何一组模态。
二、CoDi的生成模式
CoDi与现有的生成AI系统不同,CoDi可以并行生成多个模态,并且其输入不限于文本或图像等子集模态。此外,CoDi的输入和输出空间中的模态对齐,使其能够自由地对任何输入组合进行条件生成,并生成任何组合的模态,即使这些模态在训练数据中不存在。
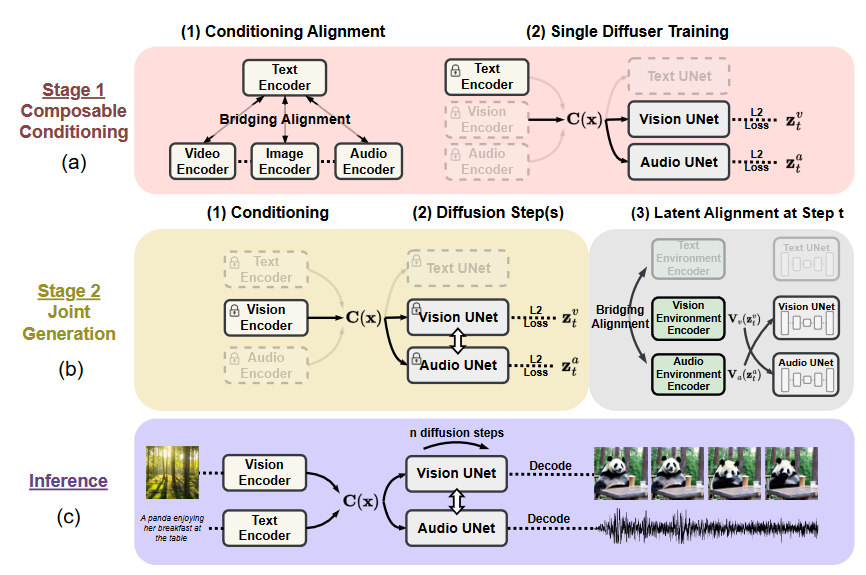
CoDi采用了一种新颖的可组合生成策略,通过在扩散过程中建立共享的多模态空间,实现了交织模态的同步生成,例如时间对齐的视频和音频。高度可定制和灵活的CoDi实现了强大的联合模态生成质量,并且在单模态合成的状态下表现优异或与最先进的单模态合成技术相当。
三、总结
多模态模型最近出现了很多,研究者需要保持学习,一般使用的人没必要看了,费脑细胞。
最后
参考文章:
声明
本文仅作为个人学习记录。
本文永久记录于区块链博客xlog。