
I-JEPA-初步拥有世界模型的图像AI
Jun 18, 2023
前言
本文简单记录介绍一下I-JEPA。
I-JEPA是一种基于图像联合嵌入预测架构的自监督学习方法。
正文
一、什么是I-JEPA
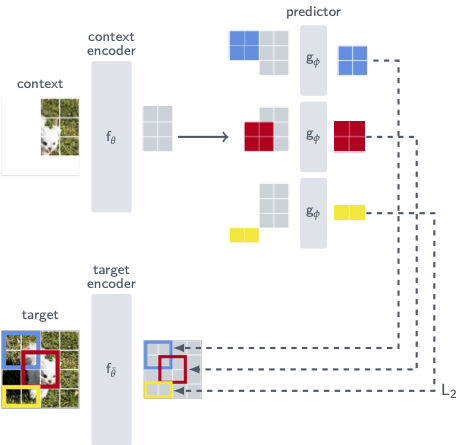
是一种自我监督学习的方法,是基于图像的联合嵌入预测架构,可以从同一图像的其他部分的表示中预测图像的一部分的表示。
二、I-JEPA功能

对于每张图像,蓝色框外的部分被编码并作为上下文提供给预测器。预测器输出它期望在蓝色框内的区域中的表示。预测器识别应该填充哪些部分的语义,从而学习对世界的语义进行建模。
需要明确的是,这个模型是预测图像中mask区域的高级信息,而不是像素级细节。
三、总结
I-JEPA是根据图像已知区域信息对不可知区域的语义级预测,项目中给的例子其实是另外训练了一个草图生成器,将I-JEPA预测到的高级语义信息进行解码,得到不可知区域的可视化预测,I-JEPA相当于一个特征提取器。这个工作与data2vec的工作感觉很类似:cry:,但data2vec引入了一个通用框架来训练不同类型的数据输入。
之所以说是初步具有世界模型的AI,是官方提到这是一个world model(喂的数据足够表示大部分图像语义)。
可能后续会有相应的其他模型发布,这只是其中一个模块。
最后
参考文章:
声明
本文仅作为个人学习记录。
本文永久记录于区块链博客xlog。